
Agile Software Part 3 - Getting the test pyramid right
Ed Mason • 12 June 2020
It isn't supposed to be upside down
Why would that happen?
This must be the most common reason for a lack of software agility that I see on a regular basis. Either the pyramid is upside down or it is a sort of diamond shape, meaning narrow at the top and bottom but fat in the middle.
This happens when the developer-based tests do not have a sufficient level of coverage, and that coverage is required in order to have a strong base to your pyramid. That's why Part 2
covered this in such detail, those tests form the basis for all testing that comes after, as well as informing what scope those later tests should (and should not) have.
The Testing Pyramid
The exact layers of a pyramid can vary, but they
all have the same basic structure:
- Bottom layer(s): Tests are faster to write and quicker to run (and are therefore cheaper in terms of time spent)
- Top layer(s): Tests are slower to write and take longer to run (and are therefore more expensive in terms of time spent)
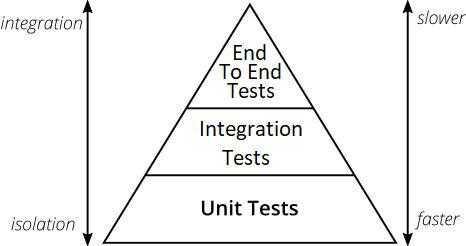
NOTE. The phrase "unit tests" is extremely ambiguous, which is why I use other more explicit terms. A Unit Testing framework can run many different types of test - functional, behavioural, integration, end-to-end, performance, etc. So, I prefer to be clear on what I am referring to.
So how do these layers
breakdown in practical terms of the tests that need writing?
- Unit tests - developer micro tests, using TDD (see Part 2).
- Integration tests (in-house) - developer integration tests for in-house components, using TDD (see Part 2).
- Integration tests (outside world) - partial system tests, ensuring components function correctly with the outside world (see Part 2).
- End-to-end tests - full system test, ensuring all system components function together correctly.
Fewer and fewer tests as you move up
The number of tests written in each layer should reduce as you move up the pyramid. This is safe to do because as Part 2 explained the lower level tests give you confidence, and guarantees as to what is covered - so there is no need to duplicate those tests again. Moving up the pyramid gives you the chance to test things that developer micro-tests cannot cover because you have more system elements together in one place.
By the time your system is in any kind of pre-production environment your tests should just be sanity checks (since all behaviour should already have been proven beyond doubt). These tests are used as much to prove the environment specific config than anything else.
It's like the stages of a jigsaw puzzle
If the idea of not testing every element at every level makes you feel a little uncomfortable, its useful to think about when you would take this approach naturally, away from the world of software. So, try thinking of it like doing a jigsaw.

- Developer-micro tests - making sure that each piece correctly fits with the piece directly next to it.
- Integration tests - making sure the picture is facing the right way up, and the picture looks right.
- End to end tests - making sure that the picture is orientated the right way round.
Practical Steps
So how do we go about implementing this in practice? How do we ensure that each layer is not duplicating effort that has already been covered in the layers below?
User Journeys / Stories / Backlog
Whatever mechanism you use to define the work you are going to do, this is the right time to think about how your testing for this feature / change / fix will look.
Your development team should have a view of the work that is coming to them in advance of it arriving, where they can understand the requirement, raise technical issues, ask questions and so on. With the team together this is also a great time for them to discuss testing.
The team should be able to discuss what will be covered by the developer micro tests. That in turn informs what would be sensible to check at an integration level (for both in-house and outside world components), and finally at the end-to-end level - as well as anything else, like performance / stress testing, security etc. The story can then state (roughly, not line for line) what testing will be done where, which could form part of the acceptance criteria. By having these discussions upfront, it helps the teams understanding of what is to be done, and where.
How big is the unit of a micro test?
This is a common question, and was partially covered in Part 2
- but not fully. For developers there are some practical steps that can be used to help determine this - the great news is that your code will help you!
NOTE. These definitions come from Sando's video in the previous post, but you know that already because you watched the video in full, right? As a reminder this section runs from 23:30-28:08.
Association types
Say you have parent class A, and class A calls child classes B and C. Is your "unit of test" A+B, or A+C, or A+B+C?
To understand this, we need to look at the child classes themselves. In this example class A has 2 associations, one to class B and one to class C. These associations could be one of two types:
- Composition
- Aggregation
The type of association tells you if it is in the scope of the unit to test. Is class B "part of" class A, or just "used by" it?
- If you merge the child class into class A would it still be cohesive (although perhaps messy)? If so then this is a Composition association, and there is no need to mock the child class, you can test is as it is.
- If you merge the child class into class A would it no longer be cohesive (meaning it would violate the single-responsibility principle)? If so then this is an Aggregation association, and the child class should be mocked for testing.
- Another way to think of this is, could the child class evolve independently from class A? If so then this again would mean it is an Aggregation association.
In short, Composition associations are part of your unit, but Aggregation associations are not - so you mock them.
A note about Mocks
Since they were mentioned in Part 2 and I've just mentioned them here, let's quickly discuss mocks.
Mocks are a valuable tool for the developer to aid their design, development, and testing. But they are commonly misunderstood or confused - the word "mocks" is often used as a general term to refer to the whole family of objects that are used in tests.
The following article from Uncle Bob
gives a fantastic explanation of what types of mocks there are https://blog.cleancoder.com/uncle-bob/2014/05/14/TheLittleMocker.html
- Dummy - a test class you call when you know the parameters will never be used.
- Stub - is a Test Double and a kind of Dummy. Use this to force a condition to be true (as an example) without having to execute all the required "real" code to make that happen.
- Spy - is a Test Double and a kind of Stub. Use this when you want to confirm that a certain part of your system has been called. But be careful here to avoid coupling.
- Mock - a "true Mock" is a Test Double and a kind of Spy. But here the assertion is moved into the mock class itself.
- Fakes. These simulate a real business behaviour, in a forced way - therefore they are fundamentally different to all the types described above. These can get extremely complicated and so they are infrequently used.
Stubs and Spies are the ones you will probably use most often. Mocks are most often used when you use mocking tools, because of how those utilities work.
As I've mentioned previously this is about knowing all the different tools at your disposal and using the right one at the right time.
Environment / configuration tests
With all this use of TDD, developer micro-tests, two levels of integration tests, and end-to-end tests you might think that everything was done. In the modern world of automated build pipelines and the cloud however, not quite.
Modern devops practices are great, and you absolutely do need them for your software to have real agility. But that flexibility comes with a lot of extra configuration, which (right now) is just a whole bunch of plain text files (YAML, JSON, etc). That means it's very easy to make a mistake.
That is why you definitely want some sanity check tests for each environment you deploy to in order to ensure that your config - rather than the functionality of your system - is working correctly. Those tests could be:
- Automated end-to-end tests
- A manual check
- System health checks
Which one is right for you is beyond the scope of this post, but you do want to make sure that everything is working when you deploy to a new environment. And yes, that
absolutely includes production!
Non-Functional Requirements (NFRs)
The user journeys / stories mentioned above should also cover any NFRs that your system may have - number of users to support, peak number of transactions to support per second, security requirements, etc. These tests are also part of the pyramid but where exactly they fit depends on your specific circumstances.
I mention them here for completeness and so that you don't forget them (!).
Summary
Done incorrectly the test pyramid is like dragging a weight behind you. Your main source of feedback comes towards the end of your pipeline, often hours (or even days) after the changes have been merged. Higher level tests are more fragile (due to environment config, the complexity of data setup and so on) which means they will need a lot of attention and re-running, possibly taking another couple of hours (or days) again. This leads you away from software agility due to the delays in confirming that your tests pass - if they ever all do.
When implemented properly the test pyramid is a great thing. It helps you focus on starting your testing with the cheapest and quickest tests to write, adding in the increasingly slow and expensive technologies as you move up the layers. This will give you fast feedback where you need it most (in front of the developer) while helping you quickly prove that the whole system hangs together correctly in your higher test environments.
If you want to be able to release your software regularly then you need the automated testing done correctly to support that.
I hope this series of posts have shown how there is one clear route to achieving that goal.

A common problem If your team has an unprepared backlog this is almost guaranteed to cause problems. Planning meetings take ages, and it significantly increases the likelihood that your stories won't get "done" - you'll just end up with a growing pile of WIP. Not to mention the time that gets wasted with the whole team watching one person frantically typing away. Fix this by Ensuring someone or a group "own" the backlog. They should always be refining it, and have a clear understanding of what is in it, and keep it tidy (no duplicates, no tickets randomly created, etc) Refusing to start work on any stories that are not "ready". This will Mean you don't end up with a messy backlog that no-one understands, or takes ages (for many people) to clean up. Shift the focus onto regular refinement, ensuring that stories are prepared, researched fully and then understood by the team. Give you a much better chance of having your work "done" by the end of the iteration. Improve conversations on priorities - changes and so on are much easier when you have a clear and ordered list to discuss. Summary I'm not suggesting this is necessarily an end-state goal, but it could help you get out of a hole and start moving towards more predictable delivery.

The first couple of blog posts were aimed at giving you some essential basic skills, building up your confidence to explore a Linux installation before you get your teeth into the actual day-to-day stuff. As a DevOps engineer, one of the key things that you will be doing includes installing / deploying software and configuring it - so, it’s important that you understand how these tasks are achieved. At this stage, I could introduce you to some DevOps tooling that you would typically use, but I’m not. Mostly because I need you to feel the pain that I went through so that you can appreciate the benefits of tools like puppet, ansible and even containerisation (Docker). What’s your flavour? There are an abundance of Linux flavours ( distributions ) from Alpine, to Ubuntu, to RedHat. Which do you use? In my opinion, it’s not that important at this stage. The differences between the various Linux distributions will be very subtle to you at this point. What is important is that you are aware that different distributions of Linux have different package repositories, and different commands to install, but they essentially do the same thing: Pull down packaged software from a central source Install it and any supplementary files such as start/shutdown & management scripts as well documentation “What is a package repository?” I hear you say. Package repositories are essentially a centralised store of pre-compiled, pre-built and pre-tested software which optionally may include such things as configuration files, management & start-up/shutdown scripts and documentation - basically, everything that you need to start using the desired software. Benefits of using a Package Manager As a rule of thumb, always install software from a reputable source using your chosen OS’s default package manager. Package managers are your client(s) to package repositories, they understand where to look for software, how to install it, upgrade it, and remove it. Installing software using the default package manager will make your life easier as they are: Tried and tested Repeatable and consistent Easily maintainable Standardised installation and configuration Have dependency management built-in; if software “a” requires software “x, y and z” then the package manager will install the required software and appropriate versions If you can avoid it, do not build and install from source as this will give you a maintenance nightmare further down the line. For example (using Ubuntu’s apt package manager) which would you prefer to perform: sudo apt upgrade nginx , or Find and download nginx source files, unpack it, read the instructions to build, configure the build, build and install it Thought you might prefer the first option! If you prefer the latter, then imagine doing this for tens of machines! Still prefer option b? Let the Package Manager do the hard work for you Using package managers to install software is quick and reliable, you can install an application in seconds and have it configured, up and running in minutes. On a Ubuntu system, you can have nginx up and running with essentially two commands: $ sudo apt install nginx $ sudo systemctl nginx start To upgrade it, $ apt upgrade nginx $ sudo systemctl nginx restart To remove it, $ sudo systemctl nginx stop $ sudo apt remove nginx How simple is that? Whichever OS you use, its package manager will allow you to install software as easily as this. The package manager client application will generally allow you to: Search for packages to install Install specific versions of software List what other applications have also been installed by it Lookup information, such as dependencies as well as where files are installed The latter is particularly useful post-install, as in some cases, you will want to know where files have been installed to and where the application’s configuration files are. So, don’t forget to RTFM ( man ) your package manager client software :-) Configuring applications Following an installation of an application, you may want to configure it. Each application will have its own specific configuration to it so there isn’t really one magic rule other than to RTFM. It’s a time consuming activity, but reading the manual can prove fruitful and potentially save you lots of time further down the line. Be armed with: Your package manager, as this will help you identify where files referenced in the manual may be found and what they do. Your newly found Linux command line skills ( https://www.ejmit.co.uk/blog/devops-must-know-utilities ) Your vim skills ( https://www.ejmit.co.uk/blog/devops-the-beginning ) Summary As a DevOps engineer, one of the many things you’ll be doing is installing and configuring software so it’s important to get to grips with the tools that will enable you to do this quickly, accurately and consistently - and using a package manager certainly simplifies this task. Shy away from installing software from source wherever you can as quite often, it is not available as it’s not supported on your particular OS and/or hardware configuration. The only scenario where you will have to consider installing software from source is with software developed by you and/or your organisation. How this scenario can be tackled is beyond the scope of this blog, however it will be covered in a future blog where I discuss containerisation, so keep an eye out for that post :-)

This post is going to continue the theme of testing (by coincidence, honestly) - but don't worry, it's a short one. GeePaw Hill often writes detailed tweets on the intricacies of software development and I found this series really hit the spot. Here he explains how it is that we really approach TDD testing. While many people many view this as black box testing (where you cannot see "inside" the thing under test) as opposed to white box testing (where you are aware of all the internals) the reality is that the testing we most commonly perform is a hybrid - grey box.
So, in the first part of this series of blogs it was suggested that you learn and be comfortable with using a shell ( bash ) and text editor ( vim ). This post follows on from that, giving you some pointers to what utilities you should familiarise yourself with. Unix Philosophy As you progress and learn / gain more experience you will realise that the Unix/Linux (*nix) landscape is made up of lots of small little utility programs, each program does something, and does it well - DOTADIW, “do one thing and do it well”. These tools share common traits, They will be accompanied by documentation They can take input from STDIN , send errors/warnings to STDERR , and output to STDOUT They are modular, and can be combined together to perform amazing things This post aims to introduce you to a few must know utilities, and how they enshrine the Unix philosophy, and will give you an idea of how they can be combined to great effect. RTFM Haven’t come across this acronym before? You will hear and see it a lot. RTFM. Read The F*****g Manual. If someone says this to you, it’s not with malice, the acronym has good intentions, the intention is that the information is there for you, you just need to help yourself, learn and teach yourself and be self sufficient - teach someone to fish and all that... Most utilities that are installed on *nix systems will be accompanied with manual pages accessed via a utility called “ man ”. Want to see what arguments and/or optional switches a utility can take? man
Introduction I read a lot of blog posts and guides about DevOps, most of these tend to cover specific tools, languages, and concepts but do not really give you any guidance on where to start on that journey, and what essential skills an engineer should have. When I was first starting out as a Software Engineer on Linux, I was fortunate enough to work with some great people who taught and imparted me with some really good, useful words of wisdom - things that have been instilled into me and I rely upon to this day. Through this series of blog posts, I’m going to give you an introduction to what skills I think you should have in order to make a success of your role as a DevOps engineer and to share with you some of those words of wisdom. What advice was given to me When I first started out as a Software Engineer, there was no concept of DevOps, neither was a “fullstack developer” a thing, you were an engineer that was concerned with literally everything, front-to-back, you concerned yourself with how to install, configure and package your applications, how to operate your custom built software in all environments including production. It was interesting and fun times and the technology world is embracing this again with “DevOps”. So, going from writing Windows based software to client/server web applications on RedHat Linux was going to be a bit of a learning curve. I learnt a lot in a short space of time and these were the starting advice given to me: Learn the basics, grow from there Learn to use a text editor, and learn it well Learn a shell, and master it Learn and understand the basics The topics here are intended to give you gentle introductions, to point you in the right direction from where you can springboard to more advanced scenarios and use cases. Learn to use a text editor As any kind of engineer you’ll be working with plain text files a LOT, they’ll be YAML or JSON, or INI, or some weird and wonderful format. These file formats often govern how an application is configured. What all these file formats have in common is that they are in plain text - easily readable and editable from any text viewer/editor, you do not need to install some proprietary software to view/edit. So, one of the very first things you should learn is how to use a text editor - preferably through a terminal, something like vim. Why in a terminal? Well, you’ll often find that you’ll be jumping into different servers ( even containers) examining their configuration files, tweaking them, restarting the services that are attributed to them. These files, for the most part, are out of reach of your favourite locally installed editor (e.g. VS Code, Atom and the like). What you can almost always rely on being available on a remote machine is vim - learn it, use it every day, and when some service breaks in production and you need to tweak a few configuration lines, have the confidence to use vim instead of rushing to install some random text file editor that you probably do not have permissions to install, or pulling the manual out to figure out how to edit a file with vim. As a minimum, learn how to do the following: Create and edit a file (Yes! Really!) Navigating a file, e.g. finding words, moving up, down, left and right, jump by word Copy (words / lines / blocks) and paste Displaying line numbers, jumping to specific lines in a file Closing the editor Opening multiple files, in tabs, in split planes (horizontal or vertical) Navigating from one buffer to the next in tab mode, in split panes For me, these are the basic actions that I tend to do on a daily basis: I like to open multiple files to compare / contrast, so I like to see more than a single file displayed at a time in a single vim session I need to be able to jump from one “buffer” to the next, making edits where required I see some warning/error about some line of text being syntactically incorrect, e.g. syntax error on line 212, so I’d want to be able to open up the file and jump directly to that line - can you imagine scrolling down to line 1053 with the ‘j’ key? Admittedly, as a beginner with vim you will find it convoluted and overly complex to use, but there’s a reason why it’s loved by many - persevere with it, and you will be rewarded. Learn the basics and be comfortable with them, resisting the urge to customise it too much as you learn the basics. Customising it too much and introducing plugins may mean that you become too reliant upon them and be stuck without them on a remote machine where you do not have the same level of freedom. Resources: Vim has been around for many, many years and fortunately, there is a lot of literature and guides on learning, using and customising vim, checkout some of the links below: http://vim-adventures.com/ learn vim by playing a game! http://vimawesome.com/ plugins for vim Learn a shell As an engineer, you’ll be spending probably 90% of your time in a terminal interfacing with some computer through commands in a shell via a terminal session; the other 10% will probably be checking your emails via an email client, chatting to colleagues via Slack / Teams etc., or searching for a fix for a problem that you’ve encountered via your favourite web browser. The shell is a very powerful tool, used properly and as your comfort level and experience increases it can be massively productive. It is critical that you familiarise yourself with a shell. There are a multitude of shells that are available for you to use, the most popular and common is bash. There are others such as ksh, csh and zsh. But which one should you learn and use? Well, we can apply the same logic as we applied to learning a text editor ... learn bash as a priority, you can quite safely assume that bash is going to be available on almost any Unix/Linux installation. Basic things you should be able to do on the shell (with Bash) include: Navigating the folder structure, e.g. changing from one directory to another Finding files and searching for files with specific lines of text Opening files for reading, either in a program or output to your terminal session Searching through your command history Chaining commands together (e.g. the output of one command, is the input of another) Again, these are basic interactions that I have through the shell on a day to day basis: Navigating the folder structure Searching for files where I know its name, but not its location Searching for files that include snippets of text Opening files to read and/or edit Repeating a long command again that I’ve executed previously Resources The below is a helpful place to start to learn about bash, giving you a gentle introduction before jumping in to a bit more advanced topics https://www.tldp.org/LDP/Bash-Beginners-Guide/html/ Summary As the first post on this subject, it was my intention not to overload you too much with information and not to give you too many pointers - yes, some of it was a bit vague, but it was done so as to wet your appetite and to give you a good foundation from which to springboard into more advanced topics. Understanding these basics techniques will be the building blocks as you become more proficient. Then, when you hit problems you are more likely to be comfortable looking up solutions online and understanding the answers that people give. The rationale for this post was mostly because I’ve worked with a large number of engineers who are great at their job, do great work, but sometimes they can get stuck with the most basic of things such as editing a configuration file on a remote machine as the only editor available is vim, not knowing where a configuration file is and not knowing how to locate it. It is amazing how much of a superhero you can be just by knowing these basics.

In my last post I talked about how software can degrade over time, which means changes take longer and become riskier. To avoid this your software teams need to use the practices of eXtreme Programming. This post is not a detailed breakdown of XP. Instead I will focus on a couple of specific areas that will help you to maintain a healthy design and code base, which in turn will help you to avoid the problems I discussed previously. Designing with TDD I'm not going to repeat what I've said before about the benefits of Test Driven Development (TDD) and why you should do it. I've also covered before why the "Refactor" stage of the "Red-Green-Refactor" cycle is critical. What I want to do here is to get into the practical detail of these ideas. Let's start with the video below, from and former colleague of mine Sandro Mancuso . In it he covers: Why TDD can help lead to good design Inside-Out TDD (Chicago style, or Classicist) Outside-In TDD (London style) If you are part of a software team in any capacity, then you must understand these concepts well. These two TDD techniques are not mutually exclusive, they are complimentary, and you need to understand how they work so that you can use the appropriate one in any given scenario. Do try to find the time to watch this in full. NOTE. Other elements of the video such as understanding component association types and how that affects your tests will be covered in Part 3.
Welcome to my first trilogy. It needs three parts so we can cover some points that are critical to your Agile software development - yet it feels like many have missed them entirely. Agile software development is about software I appreciate this sounds obvious (or even obtuse) but there is so much evidence that a lot of people have forgotten this, or even worse they never knew it in the first place. But how can you miss that? As I've said in previous posts (and the people involved in creating the Agile Manifesto are being increasingly vocal about) Agile was originally "a small idea for small teams to solve small problems". But then along came Certified Scrum Master training, and people who knew nothing about software were educated on how to run a team to do so - mostly. Scrum is a great framework - as I always say. But it does have one fairly large gaping hole in the middle of it: It does not tell you how to write software in order to satisfy the ideas it lays out Bit of an issue that if you ask me. This omission is most likely a big reason that the project management world got hold of it so firmly (and promptly turned it into something other than it was intended to be, but lets not go there today) since it did not define any technical approaches, but just how to manage the framework. Come on, is it that important, really? That's a reasonable question. Let me give you some (way too) common examples. H ave you ever heard any of these phrases before? "The code is a mess" "It's too hard to change" "No one has touched that part in months / years, and we're scared to in case it breaks something" "It's all spaghetti code" "If we change that we don't know what effect it might have somewhere else" "It's like a ball of mud" "That change will require extensive re-testing and integration testing, maybe weeks or months" And the absolute classic: "We need to re-write it from scratch" These are all signs that the quality, developer-based micro testing (also known as unit tests), developer based integration tests and most importantly the design have been neglected. And this is where you can come unstuck if you just follow the framework laid out by Scrum. Let me describe what this looks like in software terms over the life of a project. Quietly put your hand up to yourself if you've ever experienced something like this: A new project is started Progress is rapid, new features are easy to write and testing is easy Progress starts to slow a bit, but changes to existing behaviour are taking longer Bug counts start to increase and are harder to fix Things start grinding to a halt, any change to the code takes ages and causes several other problems including regression issues I'm sure we can all admit (privately, no need to say anything out loud) that we've all seen this. But why does that happen? This happens because the basics of good software development (which the group who created the Agile Manifesto were all aiming for, albeit in different ways) have been ignored, plain and simple. So, what is the right way to go about it? I've talked about the Reg-Green-Refactor cycle before, so I won't repeat myself. But that cycle is crucial to maintain good design of your code base. And the good design of your code base is crucial in order to avoid ending up in the mess I describe above. To save a lot of preamble I'll cut to the chase. If you want the benefits of Agile software development and for Scrum to work: Y ou need your software teams to be using the practices of eXtreme Programming . You just can't avoid that fact. This short video from J. B. Rainsberger is a fantastic explanation of this. It won't take you long, as you can see it has the snazzy title of "7 minutes 26 seconds".

I see a lot of people saying that change has to start with culture, and some of these posts get a LOT of likes and positive comments. But I have never seen any specifics as to how they suggest you do this. Honestly, not one. And I think there is a reason for this. What is Culture? A definition from your favourite search engine[1]: culture ( noun); plural noun: cultures - the arts and other manifestations of human intellectual achievement regarded collectively. - the ideas, customs, and social behaviour of a particular people or society. From Wikipedia [2]: is an umbrella term which encompasses the social behavior and norms found in human societies, as well as the knowledge, beliefs, arts, laws, customs, capabilities, and habits of the individuals in these groups. Humans acquire culture through the learning processes of enculturation and socialization, which is shown by the diversity of cultures across societies. From the University of Warwick [3]: ‘Culture is a fuzzy set of basic assumptions and values, orientations to life, beliefs, policies, procedures and behavioural conventions that are shared by a group of people, and that influence (but do not determine) each member’s behaviour and his/her interpretations of the ‘meaning’ of other people’s behaviour.’ Ok, I knew all that Sure, point taken. The aim there was to get a firm idea of what culture is before moving on, because while it may feel easy to define on a closer look it is much harder to pin down. The University of Warwick article alone starts with 6 definitions (from various sources) which all draw attention to different elements. Thankfully I'm not trying to come up with some uber-definition here. Phew. What I do want to point out is the common thread of words like: behaviour, manifestations, processes, procedures. Keep that in mind while we move on. Observing Culture Think about any time you have started working for a new organisation and how you learned their culture. Some may have shown you a written statement that defined it, others may not. Either way, you most likely looked for signs of common behaviours that other people demonstrated (dress code, daily hours, break patterns, personal items, ways of talking, hierarchical relationships etc). These will have either backed up the defined statement or simply demonstrated themes that people have adopted in response to the culture that is actually present. And I believe those are the traits that you will have taken on. Organisational Transformation Now let's get specific. Most of what I read agrees that if an organisation wants to under go an Agile transformation there are some key areas that you will need to address[4]: Systems Processes Culture The key points here is this - I agree with with specific order of these points. Going against the trend I agree with this order for the reasons that are explained in the associated article (see References below). So the crux of the issue that I see is - People state that change must start with culture, but they don't provide any evidence as to how that works - or approaches on how to do so. The big speech Lets say you work for an organisation, and everyone is called together for a big town hall style meeting for a major announcement. Your CEO stands on the stage and proudly states "We are going to change how we work, we are going to move away from our old waterfall ways of working to an Agile approach to deliver our software". There are charts, there are explanations, there are big motivational speeches and everyone goes away highly enthused, looking forward to this great new world and all the benefits it will bring. But then you get back to your desk, and you're still looking at the same specification document you've been working on for the past 2 months - with the same deadline in 2 weeks - for the same project that is due to complete in 15 months on which significant time and money has already been spent. You're stuck. You want to believe the new world is coming, but your boss is still pressing for the work against the existing deadlines. Nothing demonstrable has actually changed . The only way the situation will improve is when the demand for the project (in its current form) is taken away and something new is put in its place, but you are not going to achieve that with culture, you need to change the systems and processes within the company for such a huge shift to take place. By starting with concrete actions that people can actually observe like new systems (organisational design, how work is defined / prioritised), new processes (cross functional teams working on small iterations) people can see a change in the behaviour of the organisation itself. Once that is under way then absolutely you can start to introduce the idea of a new culture because people can see that changes are happening, and new behaviours are being demonstrated[5][6][7] throughout the company, which will make it much easier for everyone to buy into it. But, you can be clear that a change is coming I had an interesting conversation about this recently that highlighted an important idea. Although you cannot start a change with culture it will probably be very useful to inform everyone that a shift is coming, and to describe what that looks like and give some idea of what the goal is. This isn't trying to alter the culture at the start, but it is making clear your intention to do so, and more importantly how you intend to do it. Of course then the organisation will need to follow through on its promises and start to show it's employees that it means it. But when the actions do start then people will have both the idea of the changes and evidence that they are real, which is fantastic - the two can snowball together each giving the other added momentum. Summary Cultures are extremely important, and they are present even if they are undefined. But if you want to change one you need to give people a reason to believe that you mean it, so that they will be able to mentally adjust and buy into a change, by seeing actions and new behaviours rather than just words. Addendum - can you show otherwise? If you have an example of where culture has been changed first I would LOVE to hear from you, so that you can help me understand how it was done, and what steps were involved. Thanks! References [1] https://www.lexico.com/definition/culture [2] https://en.wikipedia.org/wiki/Culture [3] https://warwick.ac.uk/fac/soc/al/globalpad/openhouse/interculturalskills/global_pad_-_what_is_culture.pdf [4] https://www.leadingagile.com/whitepaper/ [5] https://www.tlnt.com/changing-culture-starts-with-changing-behavior/ What people actually do matters more than what they say. Therefore, to obtain more positive influences from your cultural situation, it is better to focus on changing behavior, which can lead to real culture change. Direct appeals to change beliefs, values, or ways of doing things rarely achieve the desired results, but if behaviors are changed the mindsets will follow. [6] https://hbr.org/2017/06/changing-company-culture-requires-a-movement-not-a-mandate But instead of plastering this new slogan on motivational posters and repeating it in all-hands meetings, the leadership team began by quietly using it to start guiding their own decisions. The goal was to demonstrate this idea in action, not talk about it. [7] https://www.management-issues.com/opinion/7236/changing-a-culture-starts-with-changing-behaviours/ a successful culture change relies on a clear focus on behaviours from the outset, and the behaviours need to be seen as the ‘hard’ stuff and it is important to role-model and reward desired behaviours in order to sustain them.

Processes and Teams Processes can be great, they can give you good steps to follow in order to achieve a desired result. They are especially good when the area in question is new to the people involved. I've said before that Scrum is a great framework for beginners to introduce them to some of the ideas of how to deliver software. Following a process dogmatically though can be a problem (and I've definitely mentioned that before) - but that is not the topic for today. Teams are great too, without question. I've never met two teams who are alike and getting to know a team is one of the highlights of working with a client for me. Why? Because teams are made up of a unique mix of human beings, each one different, each one bringing something else to the collective whole. 2 + 2 = 3? So, we have processes that are (or can be) great, and teams that are definitely great. We have both, we make the team implement the process so we are onto a sure thing right? Not necessarily. Well, probably not in fact. I chose my language very carefully in that sentence - specifically the word "make". Teams are the focus Here's the key point. Teams are people . A group of them, all together. And in my experience no-one enjoys being told what to do. I'm certainly not a big fan of it so I figure others are not going to be especially receptive either. Human beings are amazing, incredible, subtle, difficult, changeable and fickle things. Everyone likes to feel appreciated, valued, and know they are good at what they do (see Dan Pink's book Drive ). I'm sure you've heard people say "treat others how you'd like to be treated yourself". I like the sentiment but there are many different kinds of people who may want to be treated in very different ways, so I prefer to be a little more specific. When I deal with teams (or anyone in fact) I start* by treating them with respect, politeness, courtesy and by being friendly. I do not tell them things but ask their opinion. I may start a discussion and give suggestions on how to do something but I do not tell them they are wrong. I make sure I thank them (preferably publicly) when they have completed something well. This is how I would like to be treated so I assume it works for others, and my experience is that it does. *NOTE. I say "start" by. Over time some people may show that this does not work with them and a somewhat more direct approach is required. But I find that to be highly unusual. It is a fine art though, and you have to feel your way carefully. Every individual is completely unique, with their own thoughts, ideas, priorities, experience, strengths, weaknesses and values. And on top of that everyone's mood can change daily! So can you treat everyone the same way? Of course not. And this is where we come back to processes... Processes are nothing without people implementing them I've said in other posts that the whole point and focus of Agile is to get things done, meaning getting business value delivered into production sooner. I've also said that the processes are there to help you and not to get in the way, which means you should feel free to change / tweak / adapt them when you believe it is required. So the following statement should not come as a surprise: When dealing with teams I would rather make the most of their skills as individuals than pointlessly try and make them follow the process, forcing it on them. Why do I say this? To keep the team motivated. To show them that I value them first. And to be blunt, to not piss them off. Let me give you an example. The problem child I worked with one team who had a few shall we say, special characters. One in particular very much enjoyed seeing how far he could push people by being contentious / provocative with things he said and ways he behaved. At times it was quite disruptive to the team (until they all learned to ignore him, and then like most difficult children he soon calmed down). But while a lot of his behaviour was certainly not what you'd expect in a professional working environment he was a great developer, and I've never met anyone who cared more about their work. His work was high quality, and he did follow the steps that the team agreed around TDD and other such standards. But when a problem was found with an area of code he knew well, he really cared about that. He cared about it to the extent that he would work on fixing it on his way home on the train, he would work the evening or the weekend to get it resolved - without being asked. I should point out that while all code has bugs in it (and this was no exception) 90% of the time the issues found were with the requirements rather than the code, what had been implemented was exactly what had been asked for. So he was a very good software engineer, genuinely passionate about what he did, and doing it well. But the rest of the process? He couldn't have cared less. JIRA workflow states? Meh. Updating tickets? Forget it. So what to do? There are two choices in this situation: Let a highly skilled and valuable (despite the quirks) team member focus on what they do best, which is delivering value for the business, and fill in the process gaps around them. Hit them over the head with the process, refusing to accept anything less than all the rules (we'll ignore where those rules came from and if they even make sense) are being followed and get in their face until they do things "properly". Guess which I chose? Yep, I went with option 1. Because option 2 has another side effect I didn't mention - I keep hassling them about the process until they get so hacked off and demotivated that they leave. And when that happens, where is your process and business value then? NOTE. I'm not talking about losing an "expert" on a particular area of business knowledge, because that knowledge should be spread out among the team anyway, via pairing, reviews, design discussions etc. I'm talking about losing a very skilled and dedicated team member, then having to find a replacement who will be of unknown skill, and get them trained up to a similar standard. That process is going to take (in my experience) 3-6 months at least . EXTRA NOTE. Lots of articles say "don't be afraid to let go of your most valuable resource", and I do agree with that idea, it can be a great and very productive disruptor - and have significant medium to long term gains (and I have recommended / implemented it on several occasions). But I see that approach being necessary with people who hoard knowledge for themselves and will not share, therefore creating big bottlenecks in any process and being huge single points of failure. Yes these people may seem to have value when they are up all night saving failed releases and fixing production issues, but there is less value in that when they are responsible for the issue in the first place (especially indirectly by their earlier actions or inaction's). Something wonderful I let the status quo continue with this team because on balance they and the business were better for it, and everyone knew that. But over time a great thing started to happen. The more time that those team members spent together and really did adopt to Agile ways of working, they also became more familiar with each other as individuals. I stopped asking this one developer about the process and was doing it for him, but over time the other team members picked this up for me (without being prompted) and hassled him about it until he eventually adopted the processes himself. I loved seeing this, because even the gentle back and forth between them showed that the team was getting on together, and this in turn led to easier processes for everyone because they knew the job and just got on with it. Summary Process is great and we absolutely do need it. But it's nothing without the people to implement it, so I will always chose to focus on fostering a great team spirit and encouraging (sometimes verbally, sometimes by example, and sometimes by sitting back and waiting for someone to step in) great camaraderie. Given the options above I will always chose to favour getting the most out of a team in any way I can over rigidly trying to follow a process - because I have always found that teams appreciate it more and the business get their value delivered sooner. So treat your teams like they are your most precious resource. Because if you want to delivery quality software, regularly, to create business value, they are.

Right now we find ourselves in very different times than we are used to, but it is important that we find ways to adapt. With a now largely remote IT work force training has never been more important, while also being extremely convenient for everyone to access. At EJM IT we specialise in tailor made, bespoke training for whatever your business needs may be. Examples of the training we can offer includes: Agile introduction or refresher Advanced Scrum subjects, dealing with teams, sprint problems or how to manage your project at scale Making the process process work for you Check out our Training section to see more on what kind of training we can provide and then get in touch to have a conversation about exactly what needs you have. Remote training is available in a variety of areas, and can be one-on-one or group based, via a range of different apps. What would benefit you, your team or organisation right now? Send us a message to let us know and we will get in contact with you to discuss it further. We look forward to hearing from you soon!